







Introduction
Are you considering what your next data warehouse solution should be? When looking for a solution for a data warehouse, many features should come together, such as being easy to install, low cost, fast and stable operations, and highly secure systems. How do you select a solution that can outpace the existing platform or other traditional data warehousing solutions based on performance, scalability, elasticity, flexibility, and affordability?
For most use cases, cloud solutions are front runners thanks to their strong performance, pay-as-you-use scalability, elasticity, flexibility, cost optimization, and affordability solutions. Furthermore, by adopting a cloud data warehouse solution, businesses benefit from low storage costs, and benefit from outsourcing the challenging operations tasks of data warehousing management and security to the cloud vendor.
Top of many people’s list is Snowflake: a market leader cloud data warehouse. This article will take a deep dive into the Snowflake’s features and best practices to help you understand what Snowflake adoption means.
First though, we will take a look at the key features of a data warehouse with key features and introduce some key concepts to create a common understanding.
Data Warehouses: An Overview
The main idea of any data warehouse is to collect data from multiple sources like databases, enterprise apps, CRMs, etc. And integrate them with a single and centralized location to analyze and report on that data. Depending on the type and capacities of a warehouse, it can become home to structured, semi-structured, or unstructured data.
Structured data is organized and commonly collected from known methods and can be neatly arranged. Unstructured data comes in all forms and shapes and has no predefined format or organization, making analysis more difficult. Then there is semi-structured data which is somewhere in the middle – meaning it is partially structured but doesn’t fit the tabular models of relational databases.
What is Snowflake?
Snowflake is a cloud-based data platform provided as a SaaS (Software-as-a-Service) solution with a completely new SQL query engine. As opposed to traditional offerings, Snowflake is a tool natively designed for the public cloud, meaning it can’t be run on-premises. It is really flexible, reliable, scalable, and provides costs optimum options to store, process, and analyze your data.
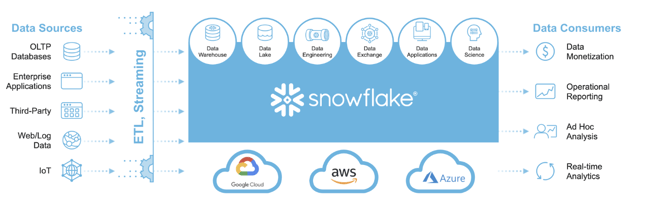
Figure 1: Data pipeline options supported by a data warehouse. Image from Snowflake
Snowflake’s Architecture
If you want to build a scalable data warehouse, you need massively parallel processing to handle multiple concurrent workloads. Snowflake uses massively parallel processing-based computing to process queries concurrently, with each node locally storing a portion of the entire data. The data ingestion, compression, and storage are fully managed by Snowflake. The data layer is completely separate from the computing layer; as a matter of fact, the stored data is not directly accessible to users and can only be accessed via SQL queries. You can see the general architecture of Snowflake below.
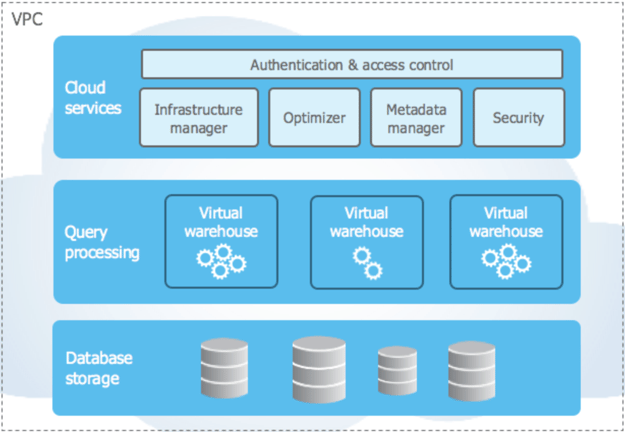
Figure 2: Data layer and compute layers provided by Snowflake Image from Snowflake
There are 3 layers that Snowflake provides:
- Data layer: the database storage
- 2 compute layers: composed of query processing and cloud services
Data may be added to the database in scheduled bulks or batches. The database storage handles tasks with secure and flexible storage of data from different sources. Data is optimized and compressed into an internal columnar format during the load. That data is stored in cloud provider buckets like Amazon Simple Storage, Azure Blob Storage, or Google Cloud Storage, etc., and, as mentioned above, this stored data is not directly accessible to users and can only be accessed via SQL queries.
Query Processing enables users to execute various SQL queries and statements. You can execute multiple queries and handle them with multiple compute clusters in parallel. As per Figure 2, Snowflake calls those compute clusters virtual warehouses. The resources (CPU, memory, storage, etc.) of those virtual warehouses are required to perform SQL operations. Users can implement CRUD operations, load and unload data in tables, and retrieve rows from those tables. You can choose your computer size on virtual warehouses and increase the computing power on those machines.
Finally, the cloud services coordinate many activities like authentication and access control, infrastructure management, SQL compilation, encryption, etc., all in Snowflake.

Snowflake’s Features
Snowflake provides many helpful features like caching data, zero management, security, scalability, data protection, easy integrations, low costs, etc. And that zero management part is no small claim: you do not have to lose time in operational and management processes.
Snowflake’s security is unparalleled, which is why customers trust the solution. Also, there are two advanced features for data protection which are time travel and fail-safe. Time travel helps to restore schemas, databases, and schemas from the past. The fail-safe feature allows for protecting and recovering historical data.
The scalability and separation of compute and storage layers enables Snowflake to run a virtually unlimited number of concurrent workloads against the same, single copy of data. This means that multiple users can execute multiple queries simultaneously.
Data caching is another feature of Snowflake – with virtual warehouse memory used for caching too. There other options for caching on Snowflake: result caching and remote disk. Result caching holds the results of every query executed in the past 24 hours. So, should users execute the same query within that period, the query result will be taken from cache, provided the underlying data has not changed. The remote disk is for long-term storage and is generally used for permanent data.
Because Snowflake is completely serverless, users do not need to manage any operational aspects of the datawarehouse: the platform handles all the management, maintenance, upgrades, and tuning tasks. Users can get up and running Snowflake easily – and start to use it within minutes. That is what is meant by Snowflake being zero management.
Another valuable feature is that it is easy to integrate and connect to the Snowflake via its web UI, command-line interface, and connectors. Connectors enable integration with third-party tools and programming drivers such as JDBC driver for JAVA, ODBC driver for C and C++, and the Python connector to connect Python apps, etc.
Snowflake Best Practices and Cost Optimization
Cost usage is probably one of the most important considerations when considering your future data warehouse system. Snowflake has some best practices that enable users to manage compute costs and optimize the total cost of usage.
Size of virtual warehouses
Compute costs of virtual warehouses depend on their size, so the best choice is to start with an x-small virtual warehouse and run queries on it. After that, you can monitor your usage, and if you need a larger virtual warehouse, you can upgrade it.
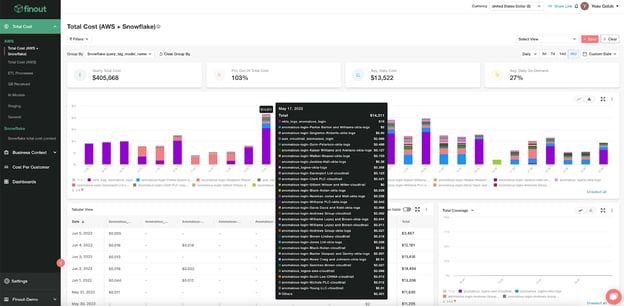
Figure 3: Managing AWS-hosted Snowflake with Finout’s cloud cost monitoring solution
Suspend virtual warehouse when the compute resource is idle
Users can monitor their compute usage in their virtual warehouses, and if the CPU is idle in those virtual warehouses because there are no queries running on it, you can suspend them and avoid the extra cost. Alternatively, you can activate the auto-suspend future on Snowflake for the idle virtual warehouses. The minimum auto suspension time users get from Snowflake's web UI is 5 minutes.
Resource Monitoring
To monitor the virtual warehouses is really important to know the usage of compute resources. Users can create alerts while monitoring those resources and take action upon reaching the monthly credits consumption threshold.
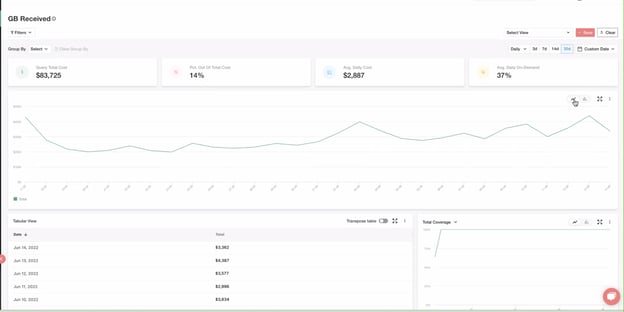
Account Monitoring
If you have a big BI and data team, it is important to monitor their account usage. Admins can check query and warehouse metering history. For example, you can check which queries run many times and how many minutes are taken while running that query. This can assist you in identifying whether anything is going wrong and as well as provide an overview of your queries. Also, this helps track the credit consumption and identifies workloads that took the maximum time over a period.
Using the Copy Command Carefully
Do not load heavy files on Snowflake. Instead, it is better to break a single heavy file into multiple smaller chunks and load them using the COPY command. Snowflake divides the COPY command workload into parallel threads to load multiple files simultaneously. This requires less time in computing the virtual warehouse and means paying fewer Snowflake credits than loading a single, huge file.
Cloud Provider Region Selection
It is always best practice to store data on your cloud provider according to the optimum region. By choosing the closest region, you will save time while transferring data, and it will reduce costs automatically.
Group Similar Workloads in the Same Virtual Warehouse
Grouping similar workloads is how Snowflake runs its own internal instance. It’s an effective strategy because you can tailor configuration settings that impact efficiency without worrying about cutting too deep. These settings include auto-suspend, auto-resume, scaling policy, clusters, and statement timeout.
Drop Unused Tables
If you do not drop those unused tables, the compute resources assigned to query those tables and the compute resources will be wasted.
Set Account Statement Timeouts
When the warehouse is already under load, i.e., busy, then executing another query would lead to performance degradation. Instead, the query is queued and waits until the necessary resources become available. Certain parameters configure that queue timeout for the SQL query. e,g;
- A warehouse has a queued timeout of 120 seconds.
- The queued timeout for the session is set to 60 seconds.
Note that, the session timeout takes precedence.
Conclusion
More and more businesses are moving their data warehousing solution into the cloud every day, thanks to the distinct advantages the cloud approach offers over legacy technologies. The zero management and serverless structure of solutions such as Snowflake are significant factors pushing these decisions.
Are you interested in learning more about cost control in Snowflake? Then take a deeper dive into controlling costs in the cloud with Snowflake in our article: How to manage costs in Snowflake.

.svg)
