





Amazon’s DynamoDB is a fully managed key-value NoSQL data store that provides high throughput with minimum latency. It is a serverless database that can automatically scale up and down to provide millisecond response time. An increasing number of enterprises are using DynamoDB to support their business-critical workloads with varied use cases ranging from web, mobile, and IoT to gaming, ad tech, retail, and more.
This article presents the pricing model of DynamoDB and discusses ways to optimize usage and reduce costs for your workloads that use DynamoDB as a datastore.
Amazon DynamoDB Pricing
DynamoDB charges for reading, writing, storing data, and for any optional features you want to enable. The actual pricing model of DynamoDB depends on which of the two capacity modes you opt for: on-demand or provisioned.
With the on-demand capacity mode, you pay per request for the reads and writes executed on the tables by your app. There is no need to specify the read/write throughput; DynamoDB handles the resources to ensure your workload can handle varying demand. This is a good fit for unpredictable workloads and does not require any capacity planning or prediction.
With the provisioned capacity mode, you must define the number of reads/writes per second the application requires. This differs from on-demand pricing since you pay for the provisioned capacity irrespective of the actual usage. In addition, you can leverage auto-scaling to adjust the table's capacity based on the application’s utilization, thereby enforcing cost optimization measures. It is a good fit for workloads with predictable traffic.
It is recommended that you start with on-demand capacity and observe the utilization metrics. If the application traffic pattern is predictable, you can switch to the provisioned capacity mode.
Figure 1 shows the AWS Cost Explorer interface that lets you visualize the monthly cost of a sample DynamoDB infrastructure over six months. You may group the cost by usage type to better understand the DynamoDB cost breakdown in terms of WriteRequestUnits, ReadCapacityUnits, Storage, etc.
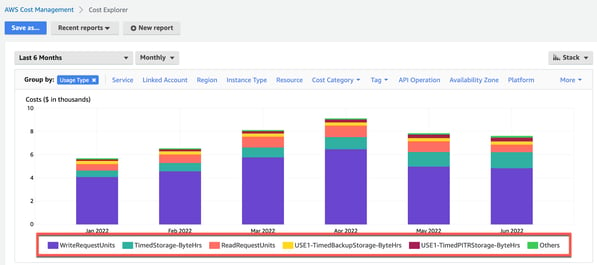
Figure 1: DynamoDB cost by usage type
Amazon DynamoDB Autoscaling
Database workloads generally have varying load patterns, hence the need to scale capacity based on incoming traffic. Provisioning static read/write capacity unit values for database capacity is not ideal for spiky and unpredictable workloads. From a cost optimization perspective, it is essential not to over provision database capacity just to ensure that you meet service level agreements. At the same time, you cannot afford to have downtime or performance degradation for production workloads while modifying database capacity.
With DynamoDB, you can dynamically manage the throughput capacity and lower costs by implementing autoscaling. This requires setting up an autoscaling policy for the DynamoDB table to modify read/write capacity based on changing traffic, as per Figure 2. You are even able to specify the secondary index you want to manage, capacity type (read/write) to operate, the upper and lower throughput range, and the target utilization.
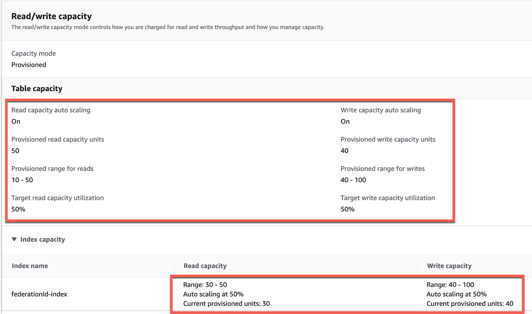
Figure 2: Autoscaling policy for DynamoDB
Once you enable autoscaling on the existing tables, you can view the scaling activities as your application serves real-time read/write traffic, see Figure 3.
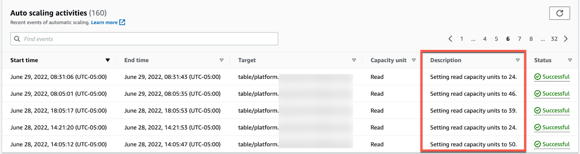
Figure 3: DynamoDB autoscaling activities

Amazon DynamoDB Reservations
If your application has a predictable traffic pattern, you can purchase a reserved capacity that offers significant cost savings over the on-demand capacity mode DynamoDB pricing. However, remember that you will need to pay an upfront fee and an hourly rate for the entire term of the reserved capacity.
Purchasing reserved capacity that applies within a single AWS region for a one-year or three-year term provides a significant discount. The only catch is that with reserved instances, you pay for the entire term whether you use it or not. As shown in Figure 4, the smallest reserved capacity you can buy is 100 capacity units (reads or writes).
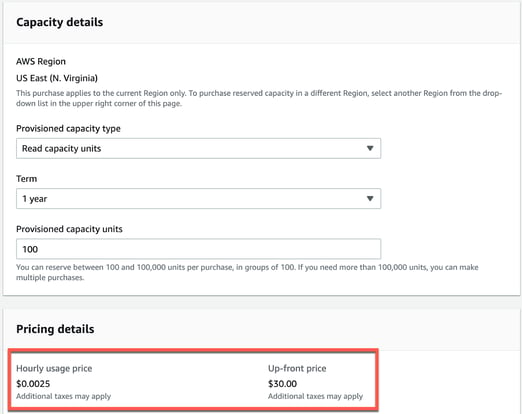
Figure 4: Purchasing reserved instances
Amazon DynamoDB Standard-Infrequent Access
With datasets growing exponentially, there is a high probability that your data storage cost exceeds your database's throughput (reads and writes) cost. However, deleting old data is not always an option to save on storage costs since it may drive some functions of the customer experience.
Many customers have use cases where old data is accessed, but infrequently. Unfortunately, the solution of putting older data into (cheaper) cold storage creates complexity – since the application would need to interact with various data stores depending on the age of the data. Also, the performance and response times often can’t be compromised even for old data – again removing the option of having different data stores for hot vs. cold data.
The Amazon DynamoDB Standard-Infrequent Access (Standard-IA) table class (Figure 5) is a new feature for when your storage cost exceeds the throughput cost. It can help reduce your total storage cost by up to 60% while retaining all your data inside DynamoDB. In addition, there are no performance trade-offs, and the Standard-IA tables offer the same durability, availability, performance, and scalability as existing DynamoDB standard tables.
The image below shows the two table class options displayed when you try to create a new DynamoDB table: DynamoDB Standard and DynamoDB Standard-IA. DynamoDB Standard is the default class and is suitable for most use cases, while a Standard-IA table class is ideal for optimizing costs for those storage-heavy workloads.
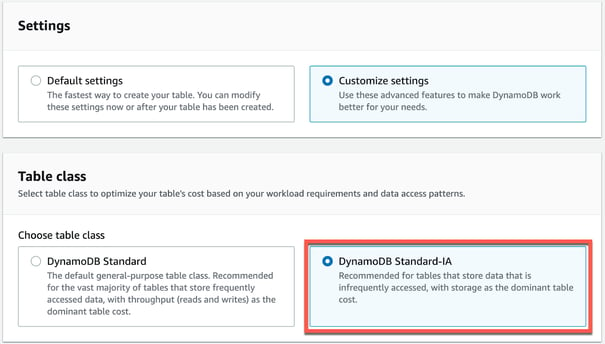
Figure 5: Selecting the DynamoDB Standard-IA table class
Monitoring DynamoDB: CloudWatch Metric
Amazon’s CloudWatch provides visibility into the performance of your DynamoDB instances. By default, DynamoDB metrics are sent to CloudWatch automatically and display real-time metrics, allowing you to investigate any performance issues. In addition, these metrics get stored for an extended period, meaning you have historical data to monitor the functioning of your application and discover trends.
In this section, we’ll look at several critical CloudWatch metrics to monitor the health of your DynamoDB tables.
Throttling
DynamoDB throttles requests when the number of calls exceeds the provisioned write capacity for the table. When throttling occurs, reads and writes to a DynamoDB table are impacted, so you should monitor throttling events and take the necessary steps to prevent them (see Figure 6). It is important to design the partition keys in the table to distribute the workload evenly. Also, while uploading data to a DynamoDB table, you will achieve enhanced performance if you upload data to all servers simultaneously.
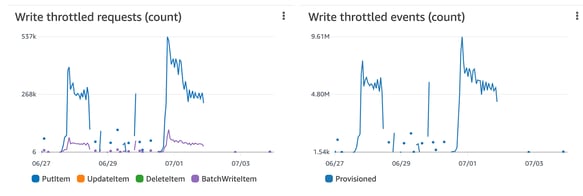
Figure 6: DynamoDB write throttled requests
Latency
To troubleshoot performance issues with your DynamoDB tables, check the latency metrics (see Figure 7). High query latency can slow down processing times and result in timeouts. You can achieve performance gains using a caching layer called DynamoDB Accelerator (DAX) if you have a read-heavy workload. Another strategy to reduce latency is using eventually consistent reads if the application does not need strongly consistent reads.
In DynamoDB, if you want to fetch a collection of items, you can use the query or scan read operation. Query performs a direct lookup based on the primary/secondary key, whereas a scan operation scans the entire table before applying filters. Hence, to improve latency, the query operation is much better than the scan.
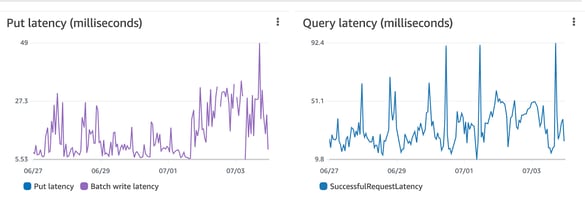
Figure 7: DynamoDB latency metrics
Deleted Items
The TimeToLiveDeletedItemCount metrics show the number of items automatically deleted by Time to Live (TTL) from the DynamoDB table during a specified period (see Figure 8). Setting up a TTL for your DynamoDB table allows you to delete data you don’t want to retain. It also helps to reduce storage costs and boost application performance since you have less data to scan.
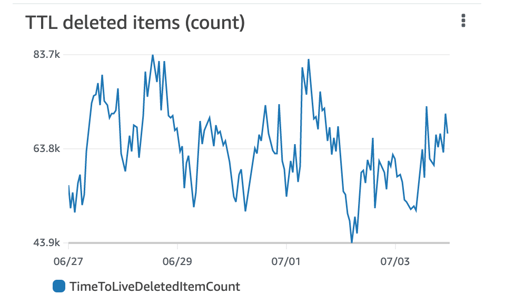
Figure 8: DynamoDB TTL metrics
Further Considerations
When architecting applications that require DynamoDB, it is vital to follow best practices from a design and cost perspective. To optimize query performance, be aware of the difference between a scan/query operation and correctly provision read/write capacity to avoid frequent spikes. Use partition keys effectively to allow for uniform activity across all keys in a table and any secondary indexes.
When it comes to truly understanding the costs of your DynamoDB infrastructure, investigate the benefits of a cloud cost observability platform such as Finout. With Finout, you can easily monitor the reserved instance coverage for your DynamoDB infrastructure with in-depth granularity from a read/write perspective.
Contact Finout today to understand how you can optimize your DynamoDB spend using Finout’s cloud cost observability platform.

.svg)
